Read and write to/from s3 using python — boto3 and pandas (s3fs)!
First, lets create a s3 bucket through Amazon AWS s3 management console. Click on “Create Bucket”.

Fill in the required details and click on “Create Bucket.

You will get a success message once the bucket is created, and the bucket will be listed on the Buckets list.

Click on the bucket name. You can upload a file directly from the UI by clicking on upload button.

Let’s use python application to upload the file on s3 bucket. But before that we need to create special user with required permissions to read and write on s3 buckets.
For that go to IAM management console.

Click on users, and click on Add users.

Provide a user name and give the user programmatic access.

Now we need to give the user permission to read and write data to S3. We have two options here. The easy option is to give the user full access to S3, meaning the user can read and write from/to all S3 buckets, and even create new buckets, delete buckets, and change permissions to buckets. To do this, select Attach Existing Policies Directly > search for S3 > check the box next to AmazonS3FullAccess.
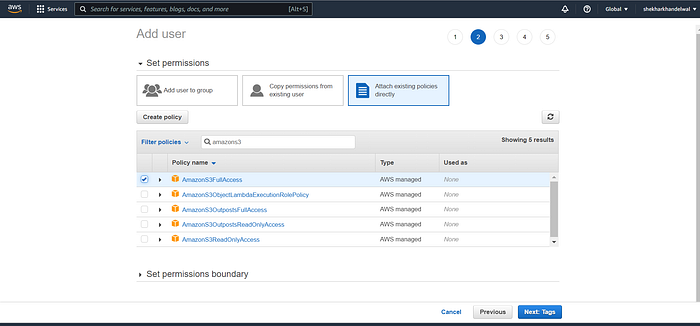
Follow the prompt and finally “Create User”.
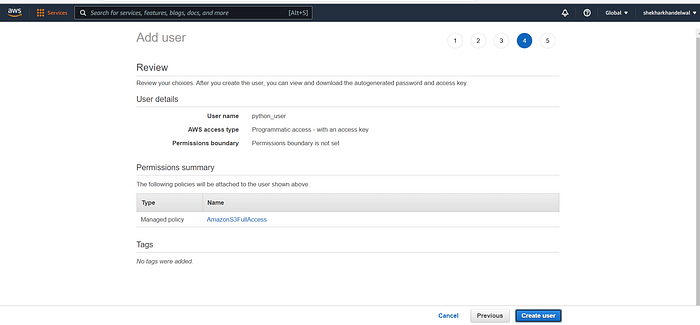
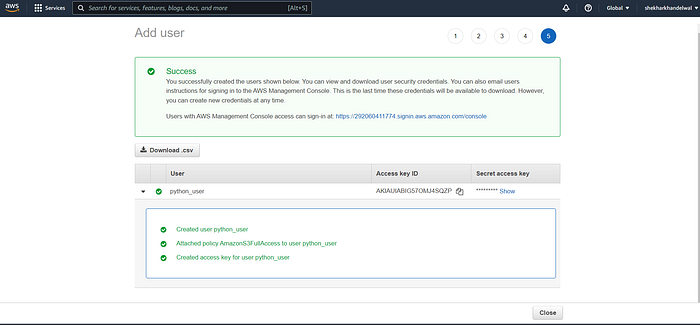
Once you get success message, before closing the page, download the security credentials, as it contains all the information required to connect to s3 from python application like Access key ID, Secret Access key etc.
There are two libraries that can be used here — boto3 and pandas. Yes, pandas can be used directly to store files directly on s3 buckets using s3fs. However, s3fs is not a dependency, hence it has to be installed separately.
!pip install -m boto3
!pip install -m pandas "s3fs<=0.4"Import required libraries.
import io
import osimport boto3
import pandas as pd
Create key variables.
AWS_S3_BUCKET = "samplebucket1303"
AWS_ACCESS_KEY_ID = "accesskey"
AWS_SECRET_ACCESS_KEY = "secretkey"Create a s3 client.
s3_client = boto3.client(
"s3",
aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY,
)Read a csv file from local filesystem that has to be moved to s3 bucket.
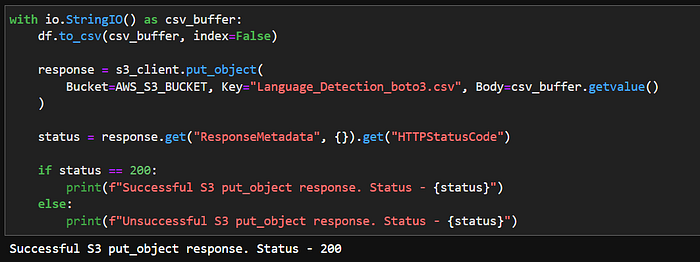
df = pd.read_csv("Language Detection.csv")Now send the put_object request to write the file on s3 bucket.
with io.StringIO() as csv_buffer:
df.to_csv(csv_buffer, index=False)response = s3_client.put_object(
Bucket=AWS_S3_BUCKET, Key="Language_Detection_boto3.csv", Body=csv_buffer.getvalue()
)
status = response.get("ResponseMetadata", {}).get("HTTPStatusCode")if status == 200:
print(f"Successful S3 put_object response. Status - {status}")
else:
print(f"Unsuccessful S3 put_object response. Status - {status}")
Check s3 bucket on s2 management console to validate if file is uploaded.
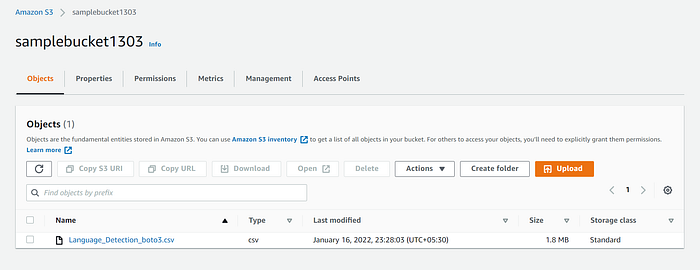
Now, lets use pandas s3fs to upload file on s3.
df.to_csv(
f"s3://{AWS_S3_BUCKET}/Language_Detection_s3fs.csv",
index=False,
storage_options={
"key": AWS_ACCESS_KEY_ID,
"secret": AWS_SECRET_ACCESS_KEY,
}
)Check s3 management console for the successful upload.
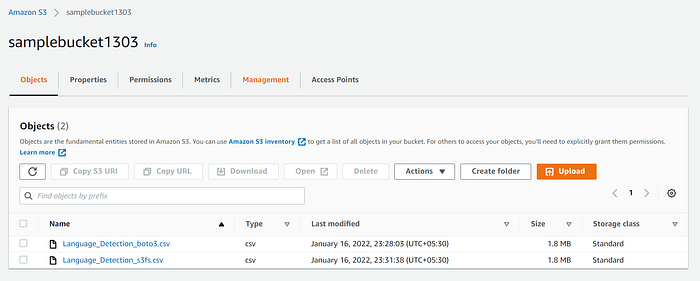
Now. lets read from s3 bucket.
response = s3_client.get_object(Bucket=AWS_S3_BUCKET, Key="Language_Detection_boto3.csv")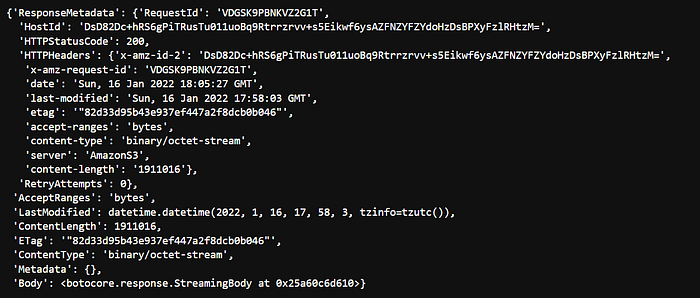
status = response.get("ResponseMetadata", {}).get("HTTPStatusCode")if status == 200:
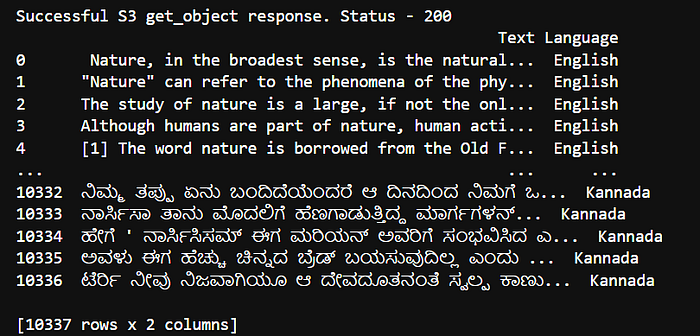
print(f"Successful S3 get_object response. Status - {status}")
books_df = pd.read_csv(response.get("Body"))
print(books_df)
else:
print(f"Unsuccessful S3 get_object response. Status - {status}")
Now, lets read directly using pandas s3fs api.
df = pd.read_csv(
f"s3://{AWS_S3_BUCKET}/Language_Detection_s3fs.csv",
storage_options={
"key": AWS_ACCESS_KEY_ID,
"secret": AWS_SECRET_ACCESS_KEY,
}
)
df.head()
Github link — AWS_series/s3 at main · shekharkhandelwal1983/AWS_series (github.com)
Happy Learning !