Deploy LLM locally using Ollama !
Jan 16, 2024
Official website — https://ollama.ai/
Github page — https://github.com/jmorganca/ollama
API documentation — https://github.com/jmorganca/ollama/blob/main/docs/api.md
Install Ollama locally
Click Download -

Choose your OS -

Open the app and click Next-

Install command line tool -

Click Finish -

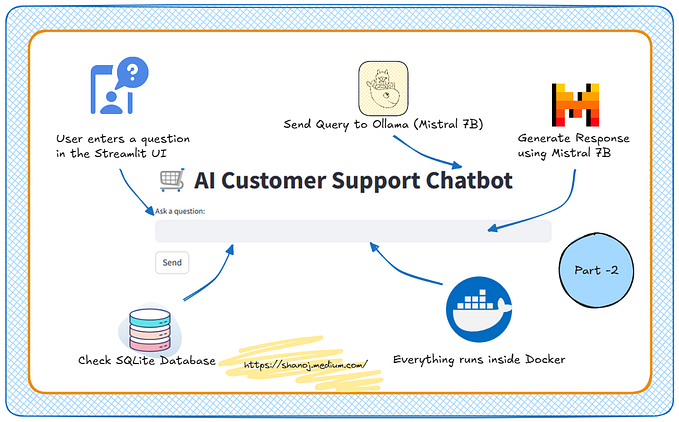
Deploy llama2 -

You can chat on the terminal directly -

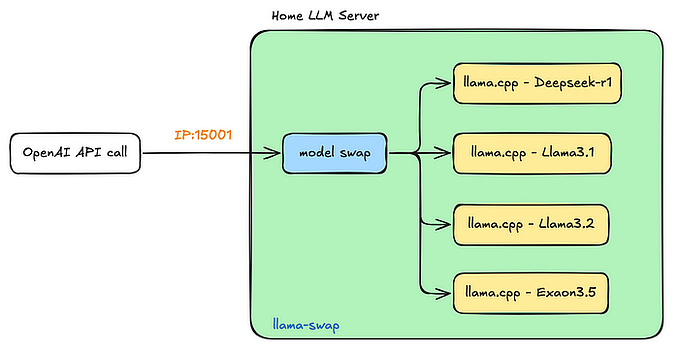
In Ollama GitHub page, you can find all the supporting LLMs that can be deployed using Ollama, their size and deployment command -

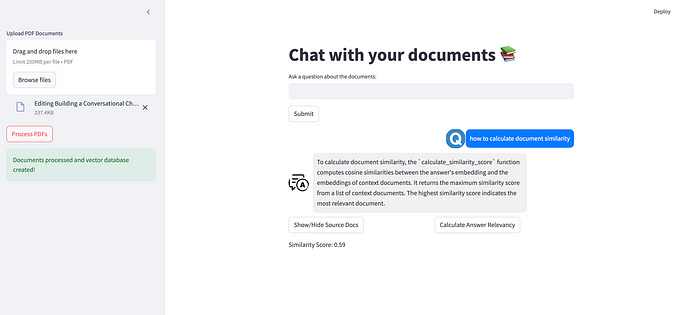
Access the locally deployed model through API

Langchain to load locally deployed model
Ollama cookbooks — https://github.com/jmorganca/ollama/tree/main/examples
Use python langchain framework to load LLMs using ollama local api -
from langchain.llms import Ollama
llm = Ollama(model="llama2")
res = llm.predict('Who are you?')
print (res)